
Outro dia, estava procurando estratégias para encontrar e extrair números em strings e cheguei a seguinte estratégia, como a mais popular, no Stackoverflow.
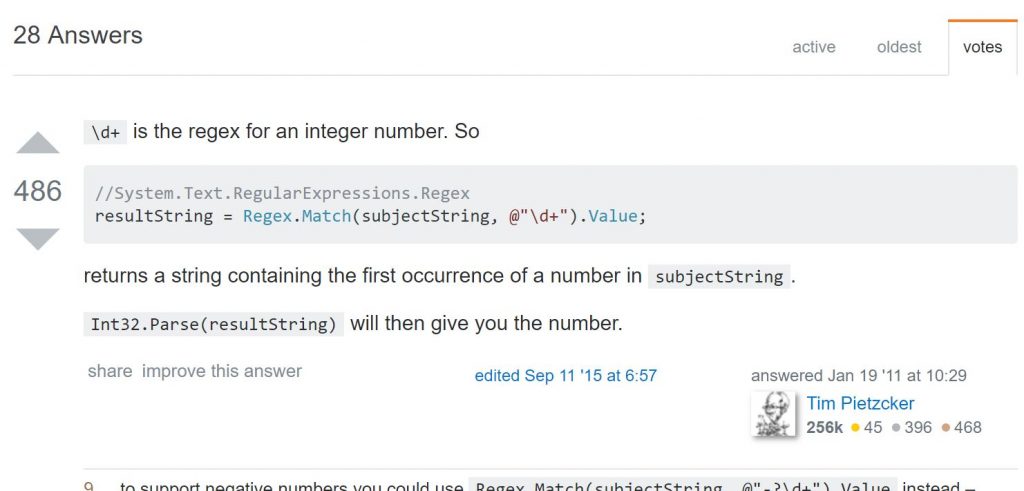
O código é simples (o que é bom). Entretanto, a Regex não compilada, junto com as alocações repetidas de strings pressionando o GC não parecem performáticas.
Resolvi fazer algumas soluções alternativas para comparação com a solução proposta. Foram elas:
- Regex compilados e parsing;
- Busca caractere-por-caractere por números, extração com substring e parsing;
- Busca caractere-por-caractere por números, extração com span e parsing;
Também resolvi comparar as performances para encontrar, extrair e converter números no início, no meio e no fim de strings.
using System;
using System.Runtime.CompilerServices;
using System.Text.RegularExpressions;
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
[MemoryDiagnoser]
public class Program
{
static void Main(string[] args)
{
BenchmarkRunner.Run<Program>();
}
[Benchmark]
[Arguments("42, starting with a number.")]
[Arguments("With a number 42 in the middle.")]
[Arguments("The secret number is 42.")]
[Arguments("42")]
public int ExtractIntUsingRegex(string input)
{
var number = Regex.Match(input, @"d+").Value;
return int.Parse(number);
}
Regex numberExtractor;
[GlobalSetup]
public void GlobalSetup()
{
numberExtractor = new Regex(@"d+", RegexOptions.Compiled);
}
[Benchmark]
[Arguments("42, starting with a number.")]
[Arguments("With a number 42 in the middle.")]
[Arguments("The secret number is 42.")]
[Arguments("42")]
public int ExtractIntUsingCompiledRegex(string input)
{
var number = numberExtractor.Match(input).Value;
return int.Parse(number);
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private static (int Start, int Length) GetNumberPosition(string s)
{
var start = 0;
for (int i = 0; i < s.Length; i++)
{
if (char.IsDigit(s[i]))
{
start = i;
break;
}
}
for (int i = start + 1; i < s.Length; i++)
{
if (!char.IsDigit(s[i]))
{
return (start, i - start);
}
}
return (start, s.Length - start);
}
[Benchmark]
[Arguments("42, starting with a number.")]
[Arguments("With a number 42 in the middle.")]
[Arguments("The secret number is 42.")]
[Arguments("42")]
public int ExtractIntUsingSubstring(string input)
{
var position = GetNumberPosition(input);
return int.Parse(input.Substring(position.Start, position.Length));
}
[Benchmark]
[Arguments("42, starting with a number.")]
[Arguments("With a number 42 in the middle.")]
[Arguments("The secret number is 42.")]
[Arguments("42")]
public int ExtractIntUsingSpan(string input)
{
var position = GetNumberPosition(input);
var numberSpan = input.AsSpan(position.Start, position.Length);
return int.Parse(numberSpan);
}
}
Os resultados obtidos foram bem esclarecedores.

Como imaginava, a performance da estratégia popular no Stackoverflow se mostrou como a menos eficiente em todos os cenários testados. Utilizar uma Regex compilada melhorou a performance consideravelmente.
A solução utilizando Substring teve a melhor performance quando a string possuia apenas o número.
A solução utilizando Span foi consistentemente a mais eficiente em todos os demais cenários (mérito por não fazer alocações e não gerar coletas). Aliás, essa estratégia de “não alocação” é a grande responsável pela melhoria de performance que temos observado em .NET.
Sugestões para tornar esse código mais performático?