
[tweet]Extrair um microsserviço de um monólito implica, invariavelmente, na revisão de como os dados são organizados e armazenados. Entretanto, é razoável postergar mudanças mais concretas até o último momento responsável.[/tweet]
Até a estabilização funcional do sistema, é recomendável que nenhuma alteração duradoura seja feita. Isso significa que os dados devem permanecer, majoritariamente, na base de dados do monólito. Dessa forma, fica mais viável, inclusive, desvincular os processos de deploy e release do novo microsserviço, direcionando o tratamento das requisições ao monólito ou ao microsserviço, através de feature toggles.
Veja também
Inicialmente, as demandas de acesso a dados do microsserviço podem ser atendidas com consultas diretas a base de dados original. Entretanto, assim que possível, o fluxo de dados deve ocorrer por uma API interna, desenvolvida para esse propósito. Nesse caso, estratégias agressivas de caching , se bem implementadas, reduzem o impacto na rede.
Veja também
- O primeiro microsserviço, no processo de transformação de um monólito, não precisa (e nem deve) ser perfeito
- Transformando monólitos em microsserviços, comece a restringir acesso as bases de dados ASAP
Com o tempo, entretanto, assim que for possível remover blocos de código que implementam features do monólito que foram desativadas em função do novo microsserviço, ficará difícil justificar o “telefone sem fio”, sobretudo em função da interdependência desnecessária entre os sistemas e, mais grave, entre os times.
Assumindo o monólito e o microsserviço como dois processos distintos, há dados que:
- continuam fazendo sentido apenas para o monólito;
- fazem sentido apenas para o microsserviço;
- dados que são de uso nos dois contextos.
A partir dessa classificação, fica um pouco mais fácil estabelecer estratégias para a segregação de bases, promovendo isolamento adequado.
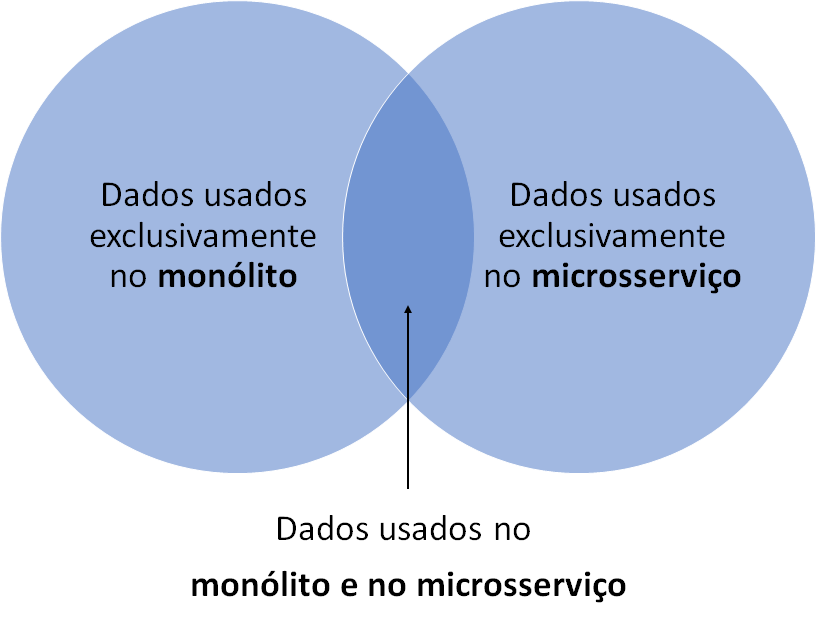
Tratamento de dados de uso exclusivo do monólito ou do microsserviço
Idealmente, a modificação de dados no sistema acontece acompanhando a execução dos processos da organização. Nesses casos, as interfaces com o usuário são naturalmente desvinculadas e os dados, associados ao microsserviço ou ao monólito, se estes estiverem bem modelados, são “inputados” de forma independente.
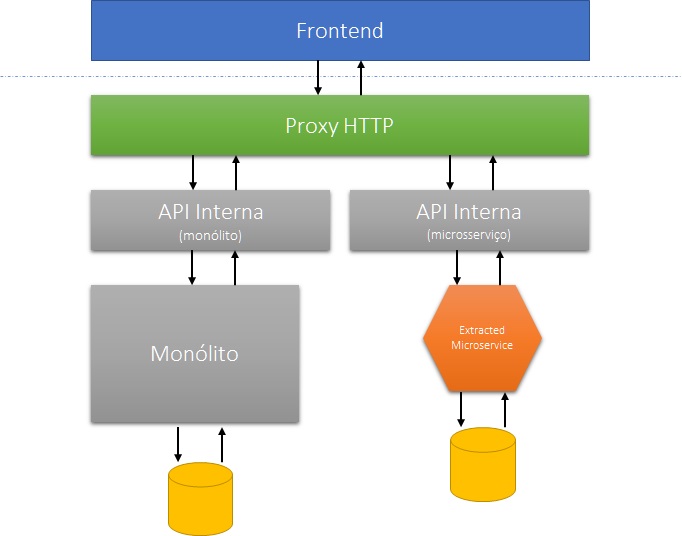
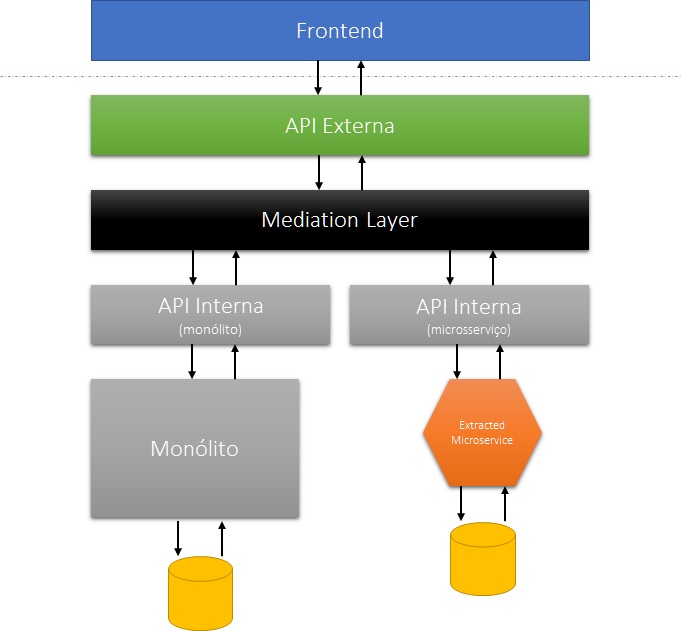
Há, entretanto, cenários onde as interfaces “acoplam” a inclusão de dados de interesse do monólito e do microsserviço a uma única operação. Isso é especialmente comum em sistemas grandes com “telas de cadastro” gigantescas. Sempre que possível, o ideal seria “redefinir” a experiência do usuário conforme o processo. Entretanto, a adequação da interface nem sempre está sob comando e controle dos times internos. Em cenários assim, o jeito é desenvolver uma API externa que continue oferecendo a “interface unificada” para os frontends, enquanto o controle da “saga” fica a cargo de uma camada de mediação que orquestra as APIs internas.
Veja também
Tratamento de dados de compartilhado pelo monólito e pelo microsserviço
Quando um dado é relevante tanto para o monólito quanto para o microsserviço, é necessário identificar em qual contexto ele “nasce”. Deve ser nesse contexto que, por padrão, o dado deverá ficar armazenado. Em caso de dúvidas razoáveis, recomendamos que a opção padrão seja gravar os dados no monólito.
A disponibilização de dados de um contexto para outro pode acontecer de diferentes formas. A mais simples, é através do fornecimento de uma API interna para consulta combinada, se possível, com alguma estratégia agressiva de caching.

Invariavelmente, nesses cenários, é relevante considerar a implementação de modelos de atualização baseados em notificações por eventos.
Conclusão
A segregação adequada dos dados diminui consideravelmente a pressão sobre a infraestrutura e reforça o isolamento entre os diversos serviços. O baixo acoplamento quanto aos dados reforça a independência dos times e da autonomia necessária para melhorias do Velocity. Entretanto, é importante que tenhamos em conta que mudanças “definitivas”, em um processo de transformação, devem ser postergadas até o último responsável.
Em última análise, não há, no longo prazo, microsserviços se há compartilhamento de bases de dados. Se isso acontece, o que temos, no lugar de microsserviços, é apenas um “pesadelo”, não justificável, para a operação.
Excelente. Utilizo da mesma abordagem.
Que artigo excelente Elemar Jr ! Seus conteúdos são de altíssimo nível e contribuem enormemente para a comunidade de desenvolvedores. Obrigado.