Quando o assunto é integração assíncrona entre aplicações e processamento de eventos em tempo real, Apache Kafka é uma das ferramentas que não pode ser ignorada. Seu ecossistema provê escalabilidade, baixa latência e boa resiliência. Sua adoção tem sido ampla, com grandes organizações optando por incorporá-la em sua stack.
Embora o Kafka seja uma excelente ferramenta, sua utilização irresponsável pode trazer dores de cabeça desnecessárias no futuro. Infelizmente, temos visto com frequência empresas adotando a solução ignorando configurações essenciais para o ambiente produtivo. São deslizes que na fase de desenvolvimento não causarão grandes problemas, mas quando submetidos ao cenário real, além de desperdiçar parte do potencial da ferramenta, acarretará em falhas relevantes.
Neste post resumimos alguns dos erros mais comuns encontrados.
Ignorar a utilização de clusters
No ecossistema do Kafka, brokers são responsáveis por intermediar o envio de mensagens entre os consumidores e produtores. Um cluster representa um conjunto de um ou mais brokers que trabalham de forma unificada com objetivo de aumentar a disponibilidade e tolerância a falhas.
O Kafka através do Zookeeper elege um dos brokers do cluster como líder, no qual torna-se responsável pelo gerenciamento de toda a escrita e leitura de mensagens em uma determinada partição. Essas mensagens são replicadas para outros brokers pelo Kafka, que por sua vez se tornam réplicas em sincronia com o líder, mais conhecidas com ISR (in-sync replica).

Em um ambiente com somente um Broker, qualquer falha pode levar a indisponibilidade total. Sendo assim, é ideal que o cluster seja composto de no mínimo 3 brokers em ambientes de produção. Desta forma conseguimos distribuir geograficamente as mensagens em regiões diferentes, assim caso alguma falha aconteça com o broker líder, conseguimos redirecionar o tráfego de mensagens para outros sem afetar a disponibilidade do sistema.
Não planejar as garantias de entrega das mensagens
Toda mensagem produzida para o Kafka é persistida internamente no broker. Dependendo do caso de uso, se faz necessário garantirmos que a mensagem de fato foi produzida e eventualmente a mesma será consumida no futuro.
A configuração ack determina quantas confirmações o produtor precisa receber do broker para confirmar que a mensagem foi persistida com sucesso. Essa configuração tem três possíveis valores: none, one, all.
O valor none determina que o produtor não necessita de nenhuma confirmação do broker. Desta forma, o produtor envia as mensagens no estilo “fire and forget”. Essa pode ser uma boa opção para casos onde é necessário uma taxa de transferência de mensagens alta, pois o produtor terá o mínimo delay entre a produção das mensagens.
Por sua vez, o valor one determina que o produtor precisa receber apenas uma confirmação para considerar a mensagem devidamente persistida no broker. Nesse caso, o produtor não precisa aguardar que todos os brokers de réplica (ISR) dentro do cluster persistam a mensagem, apenas precisa receber a confirmação que a mensagem foi persistida no broker líder.
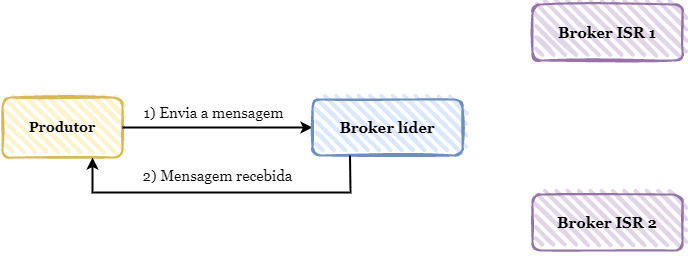
Por último, o valor all estabelece que o produtor precisa aguardar que a mensagem seja persistida entre todos os brokers dentro do cluster. Caso ocorra alguma falha em algum broker ao persistir a mensagem, o produtor receberá uma exceção indicando que a mensagem não foi persistida. Essa é uma ótima opção para casos onde precisamos de forma obrigatória garantir que o evento produzido seja processado, uma vez que a mensagem será persistida ao longo de todo o cluster e uma eventual falha no broker líder não afetará seu consumo e processamento.
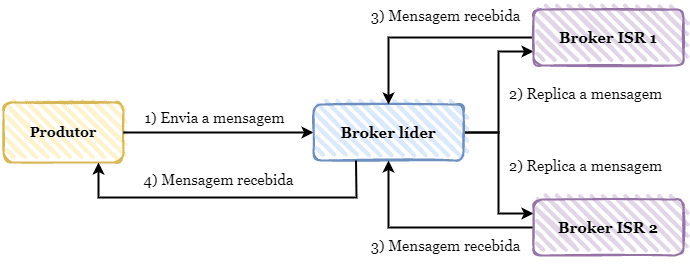
Para garantir o efeito correto do valor all, precisamos estar atento a outra configuração: min.insync.replicas. Essa configuração permite especificarmos quantas réplicas precisam estar em sincronia com o broker líder. Utilizando como exemplo um cluster com 3 brokers, precisamos especificar nesta configuração que o número mínimo de duas réplicas precisam estar em sincronia para termos o efeito desejado proposto pelo acks = all.
Não planejar a ordem de consumo das mensagens
Uma das configurações mais importantes relacionadas ao consumidor é o offset.reset. Quando um novo consumidor integra um grupo de consumidores, precisamos especificar a partir de qual offset este consumidor vai começar a consumir as mensagens.
Definindo o valor do offset.reset para earliest, o consumidor iniciaria o consumo das mensagens através do offset mais antigo, ou seja, consumiria todas as mensagens persistidas no broker. Nesse caso é importante ressaltar que podemos especificar por quanto tempo a mensagem fica disponível para consumo através da configuração log.retention.hours.
Para casos onde o consumidor precisa consumir apenas mensagens que foram produzidas a partir do momento que ele juntou-se ao grupo, podemos definir offset.reset para latest. Essa opção é ideal em casos que precisamos paralelizar o consumo de mensagens e ao mesmo tempo garantir que uma mensagem “antiga” não seja consumida com duplicidade.
Não especificar a forma de commit das mensagens
Outra configuração importante relacionada com os consumidores é o enable.auto.commit. Sempre que uma mensagem é consumida no Kafka, o offset relacionado a mesma precisa ser comitado. Por padrão, essa configuração vem habilitada, ou seja, de tempos em tempos o consumidor automaticamente realizará o commit das mensagens consumidas. A periodicidade desse commit é definida através da configuração auto.commit.interval.ms.
É necessário bastante atenção ao utilizar o enable.auto.commit, uma vez que essa configuração, quando habilitada, pode levar a perda de mensagens ou até o processamento duplicado da mesma mensagem, o que pode ser inadmissível em alguns casos de uso. Sendo assim, tenha bastante cuidado ao delegar o commit de mensagens para o Kafka.
A abordagem mais adotada ainda é a realização do commit das mensagens de forma manual, onde desabilitamos o enable.auto.commit. Nesse cenário podemos manualmente indicar que a mensagem foi processada de duas formas. A primeira delas é utilizar a API síncrona, o que naturalmente bloqueia o consumidor até que a requisição de commit seja completada, podendo impactar negativamente a performance do consumo de mensagens.
A outra forma de realizar o commit é utilizando a API assíncrona. Nesse caso, o consumidor não é bloqueado e pode continuar consumindo outras mensagens após enviar a requisição de commit do offset, aumentando o fluxo de processamento de mensagens. Porém, é preciso adotar uma estratégia para evitar commits de offset fora de ordem, o que pode, novamente, levar ao consumo duplicado de mensagens que já foram processadas.
Não entender o rebalanceamento padrão de consumidores
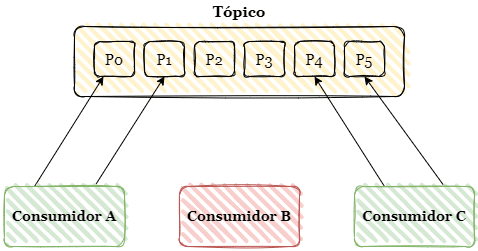
Toda partição de um tópico no Kafka pode ser consumida por um ou mais consumidores, desde que estes estejam em grupos de consumidores separados. Devido ao fato do Kafka ser um sistema distribuído, esses grupos de consumidores podem estar em brokers diferentes geograficamente distribuídos. Esta natureza permite que falhas em um dos grupos de consumidores não afetem a disponibilidade total do sistema.

Considere o exemplo acima. Se por algum motivo ocorrer uma falha no Consumidor B, os outros consumidores não serão afetados. Entretanto, precisamos atribuir as partições 2 e 3 para os outros consumidores. Essa atribuição é feita automaticamente pelo Kafka através da técnica padrão de rebalanceamento eager.
O rebalanceamento consiste em revogar todas as partições atribuídas aos consumidores e realizar a atribuição novamente de forma homogênea, uma vez que a quantidade disponível de consumidores diminuiu.
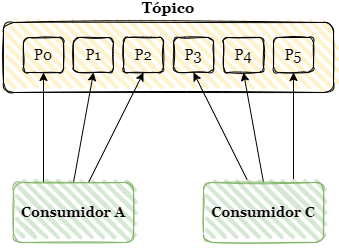
Entre o momento que é solicitado o rebalanceamento e sua finalização, os consumidores ficam em “idle”, sem a capacidade de consumir mensagens, pois dentro deste tempo estão sem atribuição de partições. Em casos como o exemplo acima não teríamos nenhum impacto significativo. Porém em cenários onde podemos ter centenas de consumidores, isso pode afetar negativamente o fluxo de consumo de mensagens, tornando o sistema indisponível por alguns minutos, o que pode ser inaceitável de acordo com os requisitos de negócio.

Em versões mais recentes do Kafka, o rebalanceamento “Incremental Cooperative” foi apresentado como uma forma de sanar o problema descrito acima. Neste formato de rebalanceamento, somente as partições processadas pelo consumidor que teve a falha são atribuídas ao restante dos consumidores disponíveis, não havendo indisponibilidade parcial no consumo e processamento das mensagens.
Conclusão
Apache Kafka é uma ótima ferramenta para a integração assíncrona entre serviços. Porém, também pode ser o seu ponto único de falha capaz de tornar todo um ecossistema indisponível. Aprender como torná-lo robusto e tolerante a falhas é essencial para seu bom uso em ambiente produtivo.
Recomendamos que entenda seus processos internos, como as mensagens são consumidas, como as garantias de entrega funcionam e como os clusters são balanceados, pois isso ajudará a evitar muitas dores de cabeça que podem custar caro.

Direto ao assunto e bem explicado.
Poderia ter outro artigo sobre o que falou na conclusão deste artigo. 😁
Parabéns!