
Nos posts anteriores, definimos “distributed tracing“. Depois, apresentamos o padrão OpenTracing e uma de suas implementações (Jaeger).
Nesse post, iremos discutir o conceito de Span (no contexto de tracing distribuído)
O que são Spans?
Citando a documentação do OpenTracing:
The “span” is the primary building block of a distributed trace, representing an individual unit of work done in a distributed system.
Each component of the distributed system contributes a span – a named, timed operation representing a piece of the workflow.
Spans can (and generally do) contain “References” to other spans, which allows multiple Spans to be assembled into one complete Trace – a visualization of the life of a request as it moves through a distributed system.
Um span inicia e se encerra com eventos específicos. Por exemplo, a interface pode abrir um span quando inicia o atendimento de uma solicitação do usuário e encerrar quando a solicitação estiver atendida. De forma análoga, o servidor pode iniciar um span quando recebe uma requisição e encerrar quando responder para a aplicação cliente. Ou ainda, podemos iniciar um Span antes de fazer uma consulta contra um banco de dados e encerrar quando um resultado for retornado.
Spans são organizados de forma hierárquica e sequencial. Ou seja, por estarem devidamente relacionados, podemos criar visualizações interessantes que nos permitem descobrir a composição de tempo e recursos consumidos.
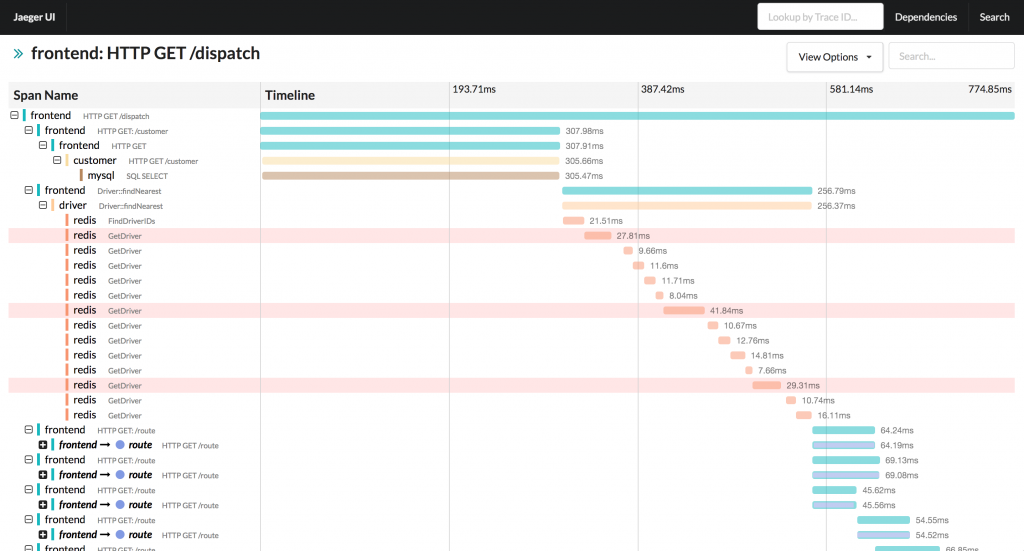
OpenTracing define um padrão coerente para que possamos definir spans, em ambientes distribuídos, como indicado na visualização entregue pelo Jaeger, mostrada acima.
Por que é importante?
O tracing de uma execução (ou atendimento de request) é fundamental para que possamos entender e resolver problemas em produção. Afinal, o tracing “conta a história” do que aconteceu (onde, quando, quanto tempo, que recursos foram consumidos). Quando estamos falando em aplicações distribuídas, a “história” acontece em máquinas diferentes, rodando, muitas vezes, aplicações desenvolvidas com tecnologias diferentes.
Analisar tracings ajuda na produção de insights para melhoria de performance. É útil, tanto quando desejamos reduzir tempos de execução, bem como quando desejamos reduzir consumo de recursos. Para isso, é fundamental que fique claramente identificado o que está consumindo mais tempo e afetando a performance.
O tracing, para ter qualidade, depende de boa instrumentação. Ou seja, precisamos garantir que todos os eventos relevantes estejam sendo registrados (de forma semelhante como faríamos em processos de logging convencionais). Entretanto, é necessário, também, que pensemos a execução como Spans (como explicado acima).
A análise, a partir dos Spans permite que “vejamos” rapidamente (e graficamente), que operações estão consumindo mais tempo e recursos.
Por enquanto… era isso
Nesse post, definimos um dos conceitos chaves para a implementação de bons mecanismos para tracing distribuído.
Nos próximos posts, vamos começar a adotar uma abordagem mais prática, mostrando como instrumentar aplicações usando as APIs do OpenTracing, usando Jaeger como ferramenta de persistência e visualização.