
Em um post anterior, indicamos que a primeira implementação de microsserviço, a partir de um sistema monolítico, não precisa (nem deve) ser perfeita. É plenamente razoável que essa primeira implementação ainda acesse diretamente, por exemplo, a base de dados do sistema monolítico. Além disso, é muito importante que o acesso ao microsserviço aconteça através de um proxy http que possa redirecionar a carga em caso de problemas.
Veja também
- O primeiro microsserviço, em um processo de transformação de um monolítico, não precisa, nem deve, ser perfeito!
- Proxy Http: um ótimo “primeiro passo” na transformação de sistemas monolíticos em microsserviços
O sucesso no cumprimento dessas recomendações indica que já foram identificados e resolvidos eventuais limitações do ambiente, sobretudo na rede. Além disso, é indicativo de que a organização já acumulou volume de experiência para operar em sistemas cada vez mais distribuídos.

Essa estratégia, entretanto, tem como principal ponto negativo o grande acoplamento entre o monólito e o microsserviço em função do acesso direto do banco de dados. Afinal, nenhum dos times (monólito e microsserviço) poderá, por exemplo, fazer ajustes no schema das bases sem causar um problema em potencial para o outro.
O próximo passo lógico passa a ser, então, “trocar dívidas técnicas caras por outras mais baratas”. Começando por restringir acesso a base de dados do sistema monolítico! Para que isso ocorra rapidamente, como se tempo e dinheiro fossem importantes, o time que mantém o monólito deverá fornecer uma API de consulta especificamente para atender as demandas do novo microsserviço.

Com o microsserviço acessando dados exclusivamente através de uma API, sem ir diretamente ao banco de dados, o time que mantém o monólito recupera a liberdade de promover modificações de schema com chances menores de quebras. Eventualmente, o microsserviço pode adotar, do seu lado, alguma estratégia de caching começando a materializar o que poderá vir a ser, em futuro próximo, seu próprio banco de dados.
É recomendável, que esse “direcionamento a API” seja controlado, no microsserviço, por uma feature toggle. Ou seja, o microsserviço deve poder redirecionar seu consumo novamente para a base de dados em casos de instabilidade.
Veja também
A partir da modelagem da API fornecida pelo monólito será possível identificar 1) dados consumidos exclusivamente no monólito; 2) dados consumidos exclusivamente pelo novo microsserviço e 3) Dados usados tanto no monólito quanto no microsserviço. Em nossa experiência, esse é um exercício muito útil para identificar falhas evidentes de segregação de responsabilidades.
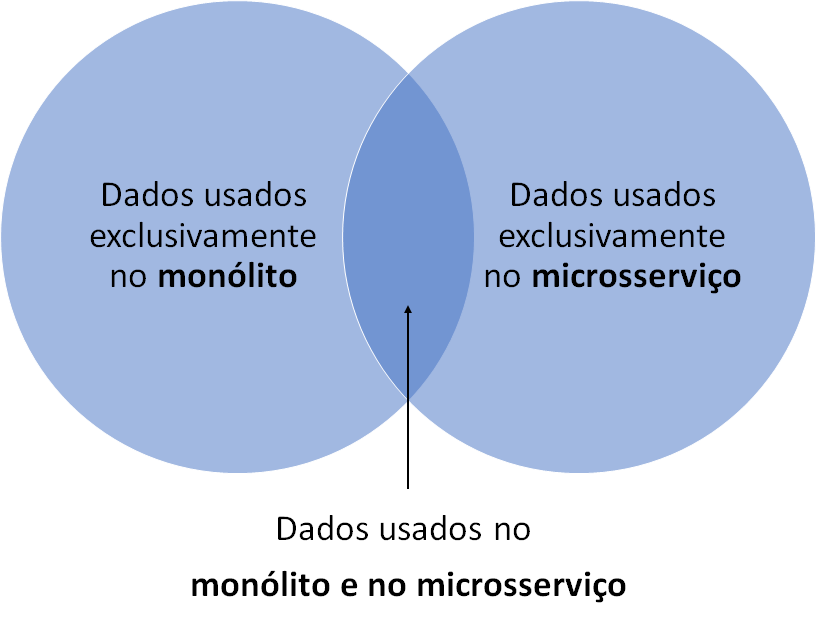
Importante destacar que o que estamos recomendando aqui é a troca uma dívida técnica mais cara (o acesso direto do microsserviço ao banco de dados do monólito) por uma mais barata (aumento da rede). Entretanto, esse é um passo intermediário importante, tanto para validação da modelagem, como para confirmar a “saúde” da infraestrutura.
Ótimo ponto de vista.
Minha estratégia não seria diferente. Inclusive havia dado uma proposta muito semelhante a um tempo atras na empresa.
Seus posts são ótimos, fazem muito sentido e seguem na mesma direção que tomaria.