Frequentemente, precisamos ter condições de fazer um tracing de um request/job. Ou seja, precisamos saber o passo-a-passo de como nossas aplicações atenderam um request ou executaram um job. Esse desafio pode ser bem complexo em cenários envolvendo microsserviços.
Nesse post, o primeiro desta série, gostaríamos de explicar o conceito de tracing distribuído, por que é importante e estabelecer correlação com o modelo de concorrência adotado.
Quatro modelos distintos de concorrência
Como indicado por Ben Sigelman, a complexidade da execução de um “tracing” depende do modelo de concorrência que estamos adotando.
Quando não há concorrência
As técnicas mais simples para tracing, ocorrem quando não há concorrência. Ou seja, cada processo é responsável por atender completamente um job/request e não inicia outro até que este esteja concluído.
Nestes cenários, a implementação de logging é trivial e o tracing é simples.
NOTA: No passado, era comum que aplicações que necessitavam atender mais de um job simultaneamente iniciassem processos independentes – um para cada job.
Geralmente, basta identificar o processo+servidor onde o request/job foi processado para que o tracing possa ser feito sem dificuldades.
Multithreading
Em cenários onde um mesmo processo é capaz de executar mais de um job/request de maneira concorrente, em threads indepedentes, o tracking fica um pouco mais complexo.
Uma saída possível e recorrente é identificar, durante o logging a thread onde um job/request está sendo executado, viabilizando, assim, a execução de consultas.
Este é o cenário da maioria das aplicações web, monolíticas, desenvoilvidas em .NET hoje em dia.
Concorrência assíncrona
Há, ainda, implementações de concorrência baseadas no modelo de atores, futures, promises, etc, que não limitam a execução a apenas uma thread.

Nesses cenários, a saída comum é fazer logging registrando algum identificador do job/request.
Microsserviços ou Concorrência Distribuída
Com microsserviços ou em ambientes de execução distribuída, um job/request, para ser completado, não “pula” apenas entre múltiplas threads, mas entre múltiplos processos (ex: quando um microsserviço aciona outro)
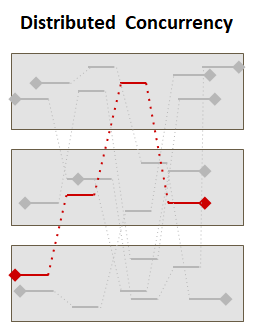
Nestes cenários, examinar o logging de cada processo, de maneira independente, não é suficiente para tracing. É necessário que tenhamos mecanismos para agregação das diversas execuções.
Além do desafio de criar um identificador único para o job/request, há ainda o desafio de tratar a sequência de execução, visto que o relógio de cada dispositivo de execução pode estar diferente.
O que é distributed tracing?
Distributed tracing é um conjunto de técnicas, padrões e práticas que tem como aspecto central o request ou o job que está sendo atendido, mesmo em atividades executadas em componentes distribuídos.
De forma breve, uma infraestrutura de tracing garante a existência de metadados de contexto, associados a cada request/job, que são compartilhados entre os diversos componentes distribuídos, durante a execução. Esses dados são, então, utilizados pelos componentes para identificar eventos “logados” na sequência certa.
Por que distributed tracing é importante?
Sem que a infraestrutura de tracing distribuído esteja bem planejada e implantada, não é possível recuperar a informação de como um request/job foi atendido em ambientes de concorrência distribuída (por exemplo, microsserviços).
Como implementar distributed tracing?
Infelizmente, não há resposta simples para essa pergunta e, por isso, resolvemos criar essa série.
Em posts futuros, vamos compartilhar ferramentas, técnicas e padrões para implementação de tracing distribuído. Iremos compartilhar o que temos visto, na prática, em nossas consultorias e um bocado de lições aprendidas.
Tem experiência com tracing distribuído? Compartilhe conosco suas visões nos comentários.

Muito bom o post.
No último projeto que trabalhei implementamos o trancing de nossos microservicos utilizando o jaegger.
Com ele foi possível monitorar passo a passo oque estava acontecendo entre, monitorar o processo, payload, tempo de execução, ordem em que os microservicos foram executados, erros e se estartaram no mesmo tempo, foi muito legal.
Ótimo artigo, alias a série toda.